My wife is really good at giving me Excel challenges to say the least. 😅
She's been spending a lot of time reviewing her open orders to locate available inventory from different warehouse locations. Her company's system apparently does not add up available inventory from different warehouses for order coordinator to process the open orders, resulting late shipment and missed sales. She has been watching Kevin Stratvert and Leila Gharani on Excel over the past couple of years and wants to link her files with Power Pivot to show the info. Somehow her file keeps telling her that there is missing relationship, and the quantity shows the total inventory, regardless of product # or warehouse location.

I receive the three reports - product report, inventory report, and the order report and jump right in. I figure this can't be that complicated because any companies dealing with physical goods and multiple warehouses will have the same challenge.
Reviewing the three reports to identify their unique identifier, if any, and their associated fields is the first thing before any analysis.
Primary key / unique identifier - product #.

Primary key / unique identifier - there isn't one. It seems we are missing some information to use this report directly as a database table. There should be another table in the system showing what products are contained in each order.
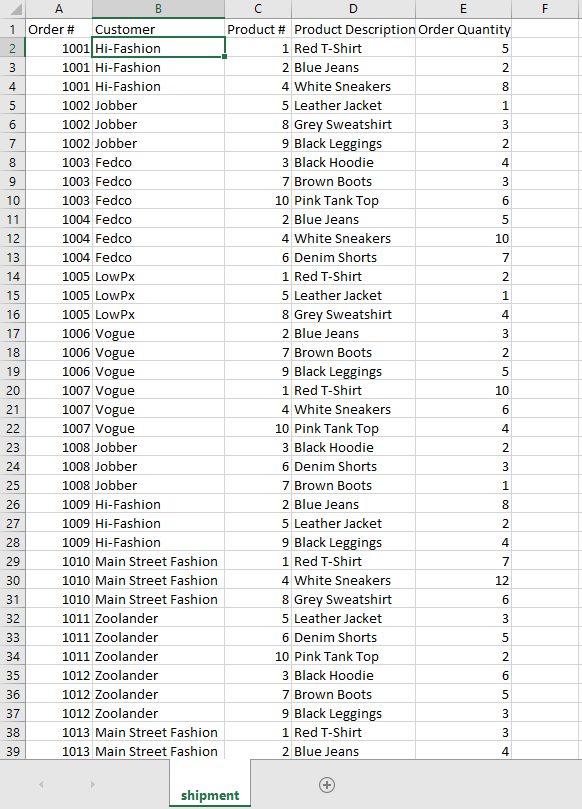
Inventory report -
Primary key / unique identifier - there isn't one. We can certain create an unique identifier using the combination of product # and storage location ID, but we will also need to create a storage location report to include all the unique storage locations.

Traditional database tables must follow certain requirements - each column in a row can only contain one value; no duplicate rows; each row must have a primary key. Two of these reports (order and inventory) do not follow the table requirement, so they were likely created with combination of tables to display the necessary information. That said, to achieve our goal to display the inventory information next to the order quantity, we can use Excel's Pivot Table and vlookup function to accomplish this task.
I generated the sample reports using ChatGPT and provided the fields I want to include, thus the same number of products in the product report are in the inventory report. We can skip loading the product report considering the inventory report is a more complete version. However, we need to reorganize the inventory report so each product only has one row, and list out each storage location and quantity in a different column for easy matching. This can be done by using using Excel Pivot Table.

(If you're not familiar with Pivot Table, Microsoft support has a basic tutorial here.)
I want to say that I'm done considering the bulk of the issue is trying to display the inventory information next to the open order, except it's not. 😬 The challenge is trying to automate the process as much as possible, so order coordinator can review the open orders and figure out how to process.
*side note* Considering how much progress Microsoft has made in the last few years to incorporate other providers into its ecosystem, I was hoping that I could easily connect to my files through Google Drive for demonstration purpose... Well, it's not. One provider charges $700+/year for 3 license for Power Pivot to connect to Google Drive. Microsoft has more work to do to expand their free connectivity with other providers!
With Power Pivot, we can either start with a new Excel file and link the two report files, or we can start with one of the report files and link in the other one. Our goal is to ensure easy update / report refresh so we must start a new Excel file and link the two report files. This way we can re-run the reports and save over old files every time to refresh the data for updated data. This should work in Microsoft share point or within a Windows network drive setup.
- To connect the files, go to Power Pivot ribbon on top and click Manage on the leftmost Power Pivot ribbon. It will open up the Power Pivot for Excel in a separate window.
 |
| Power Pivot ribbon |
 |
| Power Pivot for Excel |
If you do not have Power Pivot on the top ribbon, please see this Microsoft link for instruction.
- Click the icon From Other Sources, and scroll down to import data from an Excel file and click Next >.

- Click Browse and select the order_report_sample file and click open. Click Next >. Make sure the file is closed before you import or Power Pivot for Excel will ask you to close the file.

- Select "Use first row as column headers." because our first row is the column headers, then click Next >.

- Select the shipment$ table and click "Finish" to load the table.

- The inventory report should be loaded. Click "Close" to review the data.

- The data should be loaded.

- To get the pivot table data for the inventory, I use Power Query to transform the data and make it a table for the pivot table. Go to Data ribbon and click "Get Data" and select "Launch Power Query Editor."

- Click "New Source," then "File," then "Microsoft Excel" to link to the inventory report file.


- Select the "inventory" sheet and click OK.
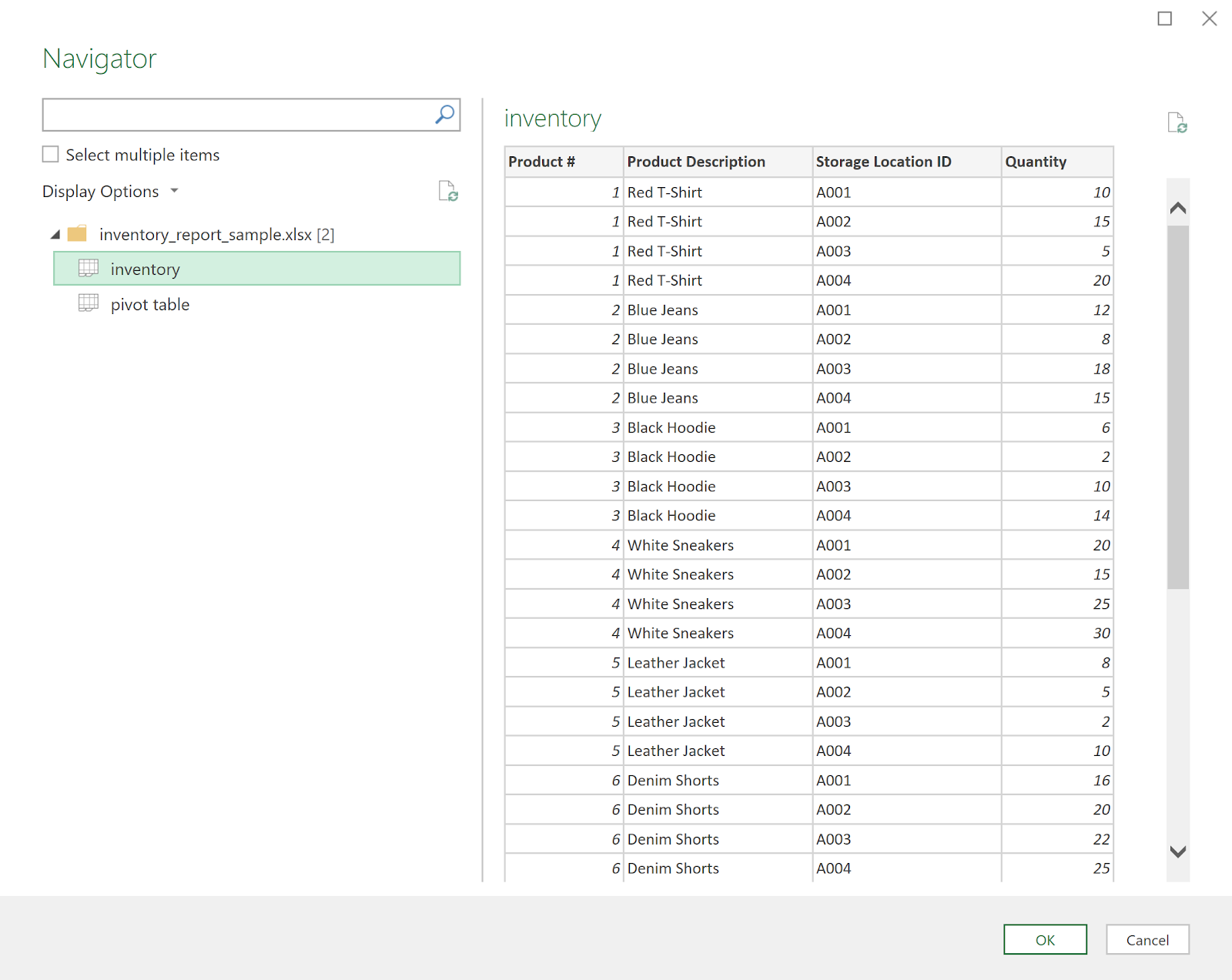
- I would change the query name so I know it's a query. In this case I change it to query_inventory and press Enter.

- I want to create a pivot table with multiple storage locations as new columns, instead of the current format showing different storage location under the same columns. The value column will be the quantity. To create this pivot table, select the Storage Location ID column, then click Pivot Column in the Transform ribbon.
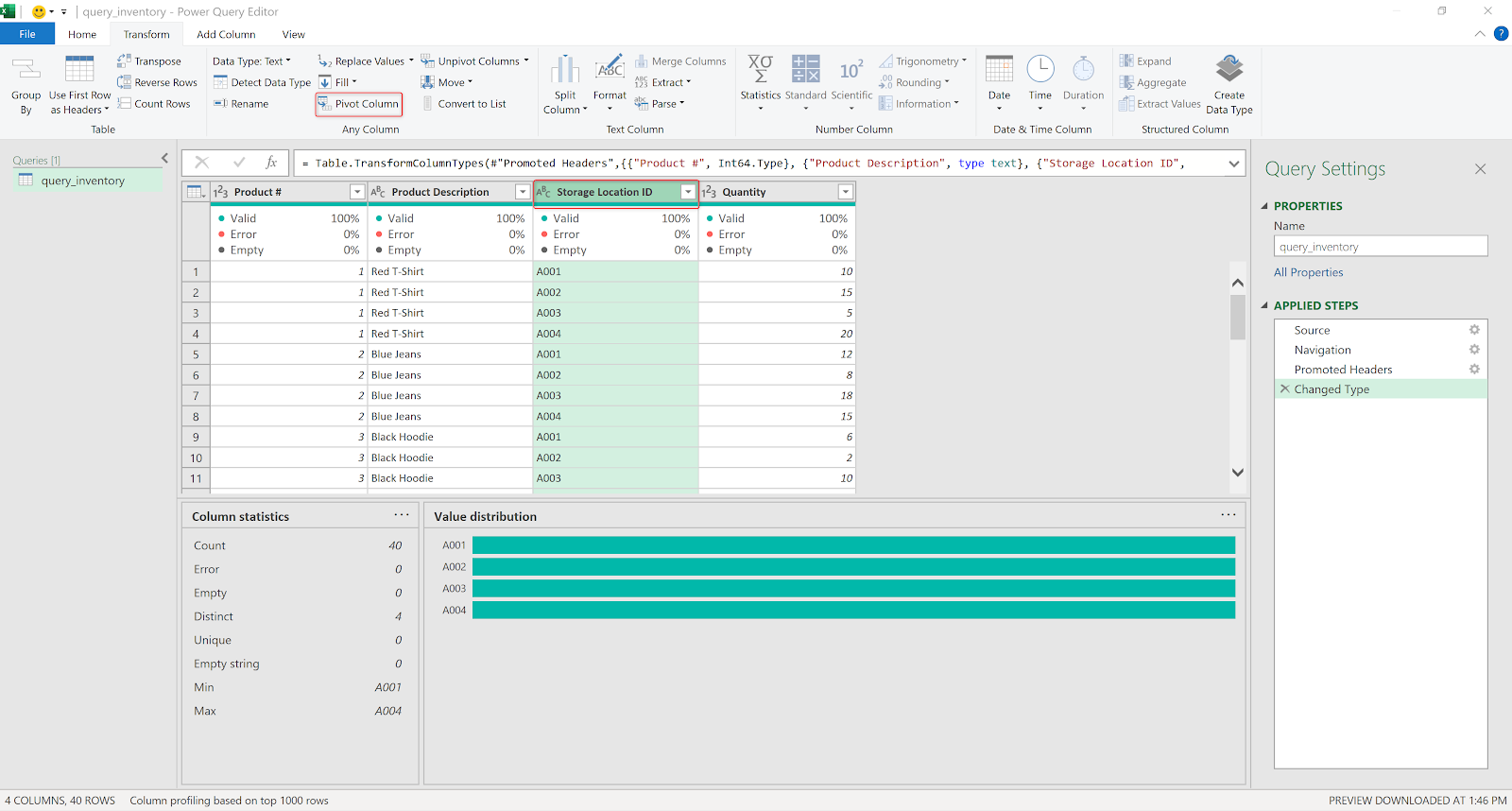
- Select quantity as the value column, check the advanced tab to ensure the quantity is added together.

- The resulting pivot table is what we need - each product # has multiple columns showing inventory at each storage location (A001, A002, A003, A004).

- Click "Close & Load" under the Home ribbon to return back to Excel.

- A new sheet with name "query_inventory" is created with the same information. To add a total_inventory column for each product #, type "Total_Inventory" next to A004 and press Enter

- In the cell below, add a formula "=sum(c2..f2)" and press Enter to add up the inventory quantity from all locations. Query_inventory sheet was created as a table so formula is automatically copied to the cells below. Noticed that even the formula is different from what I typed because it's been converted to table reference.

- To create the relationship between query_inventory and shipment table, we need the query_inventory to exist in Power Pivot data model. To do it, we can simply click "Add to Data Model" in the Power Pivot ribbon, and you will see a new tab "Table_query_inventory" created in Power Pivot for Excel.

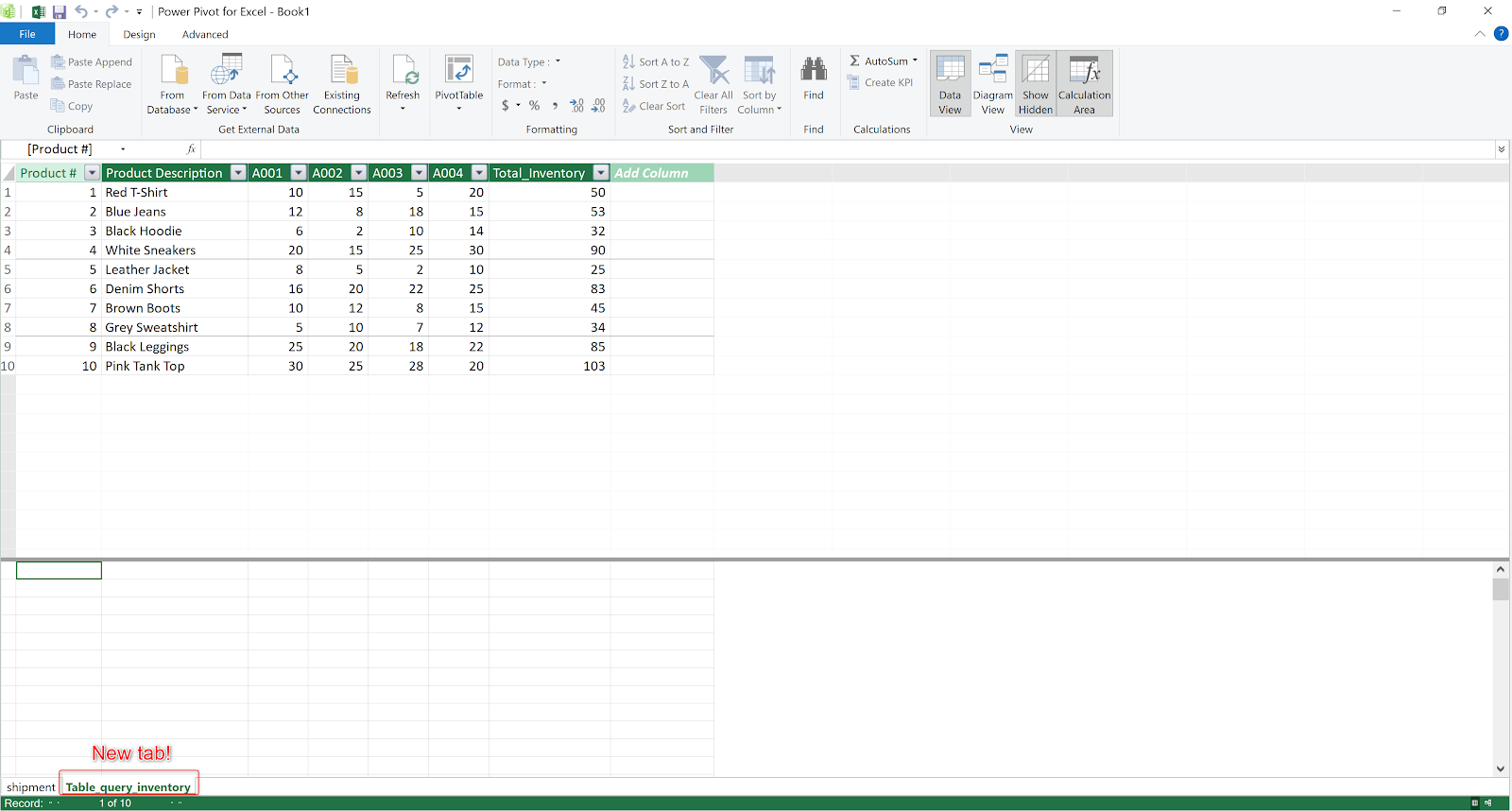 |
| Power Pivot for Excel new tab created! |
- The next step is to review and establish the relationship between Table_query_inventory and shipment table. The easiest way is to click the Diagram View in Power Pivot for Excel, and drag the Product # from Table_query_inventory to the Product # of the shipment table.

 |
| Drag Product # from Table_query_inventory to Product # in shipment |
 |
| Relationship established! |
- The last step is to create a pivot table from Power Pivot. Click the PivotTable and select PivotTable from the selection. A new pop up "Create PivotTable would show up. Select New Worksheet and press OK.


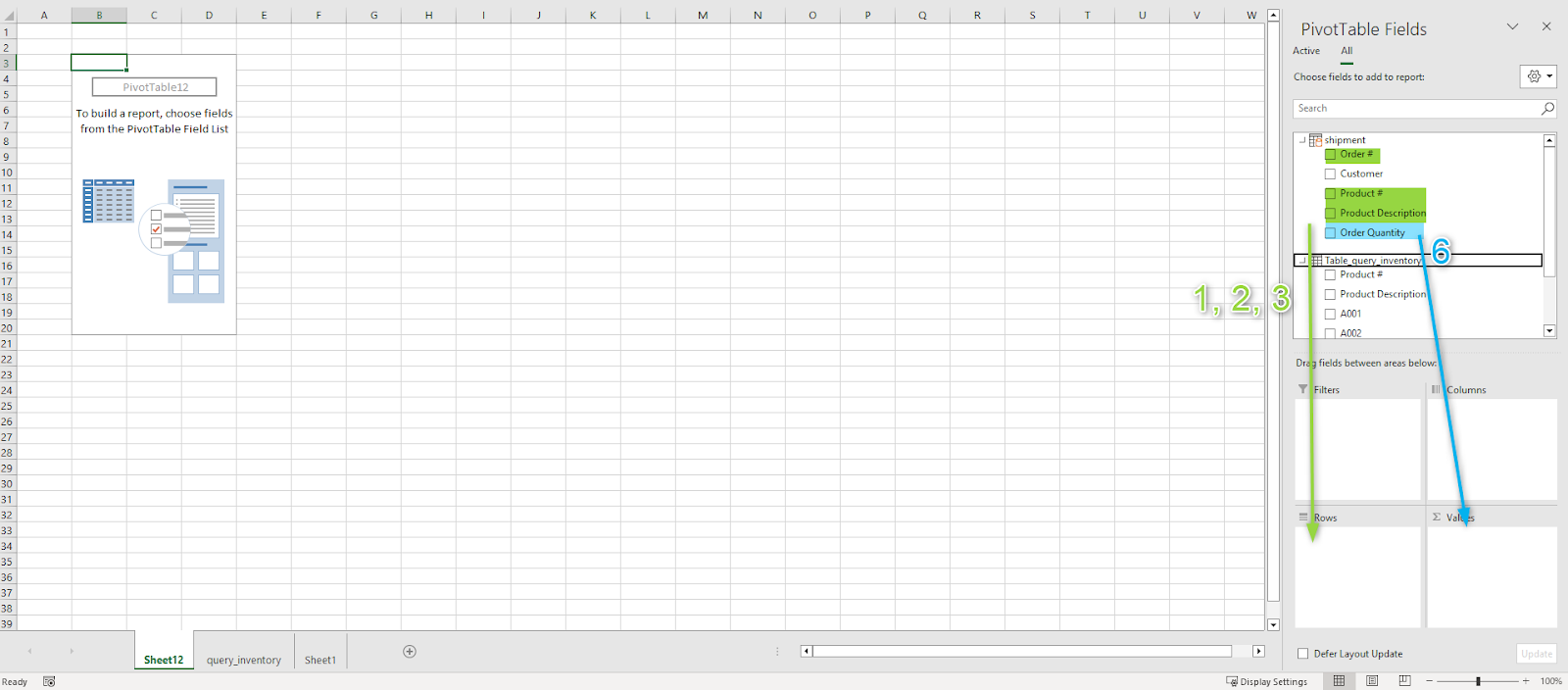
- I want the pivot table to show Order #, Product #, Product Description, Total Inventory, inventory from different locations, then order quantity for the product #. To organize the pivot table that way, we follow the order as such -
- drag Order # down to Rows
- drag Product # down to Rows
- drag Product Description down to Rows
- drag Total Inventory from Table_query_inventory down to Rows
- drag A001, A002, A003, A004 to Rows, in that order, below Total Inventory
- drag Order Quantity to Values

- The resulting pivot table doesn't look quite right, but it's easy to fix!

- Right click inside the pivot table, say around Red -T-Shirt, and click the Pivot Table Option.

- Click the Display tab of the PivotTable Options window, the select "Classic PivotTable layout (enables dragging of fields in the grid), then click OK.

- You should have a pivot table similar to what I have here now.

Data refresh -
That said, to be safe, please go to Query ribbon and manually refresh the query data before refreshing pivot table data. This will ensure the pivot data is updated. Furthermore, we probably want to change the pivot table options so that the data is updated every time the worksheet is open.

This project took me longer than I expected. I spent a lot of time trying to figure out the correct database layout, which isn't what was the original ask. I also spent a lot of time trial-and-error with Power Pivot and Power Query, until I found this short article on Microsoft site "How Power Query and Power Pivot work together"...
Possible next steps - create a report using Power Query or PowerBI, or Python.
Power Query Query Settings pane - I believe by default the Query Settings is hidden. To show this pane, go to View ribbon and click Query Settings. Then the Query Settings pane will show up. It is like a history pane showing all the steps that have been applied to this query.

Sample data created by ChatGPT.



